Redis 底层探秘
Redis 数据结构实现原理
copy from https://juejin.cn/post/6844903856313368589#heading-3
1.string
1 | // sdshdr64 变成 sdshdr32, 则相应的 len 和 alloc 变成 uint32_t |
redis 写的字符串库有以下4个优点:
- 降低获取字符串长度的时间复杂度到O(1)
- 减少了修改字符串时的内存重分配次数
- 兼容c字符串的同时,提高了一些字符串工具方法的效率
- 二进制安全(数据写入的格式和读取的格式一致)
总结: string 就是字符串, 但 Redis 其实有实现自己的类库提高各方面的速度, 只能说, 专业!!!
2.list
ziplist
ziplist并不是一个类名,其结构是下面这样的: <zlbytes><zltail><entries><entry>...<entry><zlend>
其中各部分代表的含义如下:
- zlbytes:4个字节(32bits),表示ziplist占用的总字节数
- zltail:4个字节(32bits),表示ziplist中最后一个节点在ziplist中的偏移字节数
- entries:2个字节(16bits),表示ziplist中的元素数
- entry:长度不定,表示ziplist中的数据
- zlend:1个字节(8bits),表示结束标记,这个值固定为ff(255)
这些数据均为小端存储,所以可能有些人查看数据的二进制流与其含义对应不上,其实是因为读数据的方式错了
ziplist内部采取数据压缩的方式进行存储,压缩方式就不是重点了,我们仅从宏观来看,ziplist类似一个封装的数组,通过zltail可以方便地进行追加和删除尾部数据、使用entries可以方便地计算长度
quicklist
1 | typedef struct quicklist { |
我们可以明显地看出,quicklist是一个双向链表的结构,但是内部又涉及了ziplist,我们可以这么说,在宏观上,quicklist是一个双向链表,在微观上,每一个quicklist的节点都是一个ziplist
在redis.conf中,可以使用下面两个参数来进行优化:
- list-max-ziplist-size:表示每个quicklistNode的字节大小。默认为2,表示8KB
- list-compress-depth:表示quicklistNode节点是否要压缩。默认为0,表示不压缩
这种存储方式的优点和链表的优点一致,就是插入和删除的效率很高,而链表查询的效率又由ziplist来进行弥补,所以quicklist就成为了list数据结构的首选
总结: 是一个双向链表 + ziplist, 同时具有两者的优点(指插入速度和查询速度, 具体咋回事, 怎么做到的.. 完全不知道啊).
3.hash
ziphash
zipmap其格式形如下面这样: <zmlen><len>"foo"<len><free>"bar"<len>"hello"<len><free>"world"
各部分的含义如下:
- zmlen:1个字节,表示zipmap的总字节数
- len:1~5个字节,表示接下来存储的字符串长度
- free:1个字节,是一个无符号的8位数,表示字符串后面的空闲未使用字节数,由于修改与键对应的值而产生
这其中相邻的两个字符串就分别是键和值,比如在上面的例子中,就表示"foo" => "bar", "hello" => "world"这样的对应关系
这种方式的缺点也很明显,就是查找的时间复杂度为O(n),所以只能当作一个轻量级的hashmap来使用
dict
1 | typedef struct dict { |
很明显是一个链表,我们知道这是采用链式结构存储就足够了
这种方式会消耗较多的内存,所以一般数据较少时会采用轻量级的zipmap
总结: 是个链表, 缺点是消耗内存高, 因此数据较少会采用 zipmap 这种…. 按字节精打细算的方式存储.
4.set
1 | typedef struct intset { |
其中各字段含义如下:
- encoding:数据编码格式,表示每个数据元素用几个字节存储(可取的值有2、4,和8)
- length:元素个数
- contents:柔性数组,这部分内存单独分配,不包含在intset中
intset有一个数据升级的概念,比方说我们有一个16位整数的set,这时候插入了一个32位整数,所以就导致整个集合都升级为32位整数,但是反过来却不行,这也就是柔性数组的由来
如果集合过大,会采用dict的方式来进行存储
总结: 底层是个数组的 inset 结构体, 另外集合过大会采用 dict 来存储.
5.zset
zset,有很多地方也叫做sorted set,是一个键值对的结构,其键被称为member,也就是集合元素(zset依然是set,所以member不能相同),其对应的值被称为score,是一个浮点数,可以理解为优先级,用于排列zset的顺序
其也有两种存储方式,一种是ziplist/zipmap的格式,这种方式我们就不过多介绍了,只需要了解这种格式将数据按照score的顺序排列即可
另一种存储格式是采用了skiplist,意为跳跃表,可以看成平衡树映射的数组,其查找的时间复杂度和平衡树基本没有差别,但是实现更为简单,形如下面这样的结构(图来源跳跃表的原理):
总结: 看不懂….
再看看这个吧… 更细致一点! https://juejin.cn/post/6844904192042074126
Redis 的持久化
摘记一下: copy from https://mp.weixin.qq.com/s/zfkhQFEBkKSRsfKF63R94A
RDB
写RDB文件是Redis的一种持久化方式。在指定的时间间隔内将内存中的数据写入到磁盘,RDB文件是一个紧凑的二进制文件,每一个文件都代表了某一个时刻(执行fork的时刻)Redis完整的数据快照,恢复数据时,将快照文件读入内存即可。
触发保存RDB文件4种情况
- 手动执行save命令、bgsave
- 满足配置文件中配置的save相关配置项时,自动触发
- 手动执行flushall
- 关闭redis , 执行 shutdown 命令
如何让redis加载rdb文件?
只需要将rdb文件放在redis的启动目录下,redis其中时会自动加载它。
RDB模式的优缺点:
优点:RDB过程中,由子进程代替主进程进行备份的IO操作。保证了主进程仍然提供高性能的服务。适合大规模的数据备份恢复过程。
缺点:
- 默认情况下,它是每隔一段时间进行一次数据备份,所以一旦出现最后一次持久化的数据丢失,将丢失大规模的数据。
- fork()子进程时会占用一定的内存空间,如果在fork()子进程的过程中,父进程夯住了,那也就是redis卡住了,不能对外提供服务。所以不要让生成RDB文件的时间间隔太长,不然每次生成的RDB文件过大对Redis本身也是有影响的。

总结: 每隔一段时间(一般比较久)触发的全量备份, 备份速度取决于使用情况, 备份时 Redis 仍然可读可写, 但写还是有些问题. 缺点是宕机容易丢失较久的数据.
AOF
Append Only File,他也是Redis的持久化策略。即将所有的写命令都以日志的方式追加记录下来(只追加,不修改),恢复的时候将这个文件中的命令读出来回放。
aof模式的优缺点
优点:
- aof是用追加的形式写,没有随机磁盘IO那样的寻址开销,性能还是比较高的。
- aof可以更好的保护数据不丢失或者尽可能的少丢失:设置让redis每秒同步一次数据,即使redis宕机了,最多也就丢失1秒的数据。
- 即使aof真的体积很大,也可以设置后台重写,不影响客户端的重写。
- aof适合做灾难性的误删除紧急恢复:比如不小心执行了flushall,然后可以在发生rewrite之前 快速备份下aof文件,去掉末尾的 flushall,通过恢复机制恢复数据。
缺点:使用aof一直追加写,导致aof的体积远大于RDB文件的体积,恢复数据、修复的速度要比rdb慢很多。
aof的重写
AOF采取的是文件追加的方式,文件的体积越来越大,为了优化这种现象,增加了重写机制,当aof文件的体积到达我们在上面的配置文件上的阕值时,就会触发重写策略,只保留和数据恢复相关的命令。
手动触发重写
1 | # redis会fork出一条新的进程 |
RDB和AOF的选择
- 如果我们的redis只是简单的作为缓存,那两者都不要也没事。
- 如果数据需要持久化,那不要仅仅使用RDB,因为一旦发生故障,你会丢失很多数据。
- 同时开启两者: 在这种情况下,redis优先加载的是aof,因为它的数据很可能比rdb更全,但是并不建议只是用aof,因为aof不是那么的安全,很可能存在潜在的bug。
推荐:
- 建议在从机slave上只备份rdb文件,而且只要15分钟备份一次就够了。
- 如果启动了aof,我们尽量减少rewrite的频率,基础大小设置为5G完全可以,起步也要3G。
- 如果我们不选择aof, 而是选择了主从复制的架构实现高可用同样可以,能省掉一大笔IO操作,但是意外发生的话,会丢失十几分钟的数据。
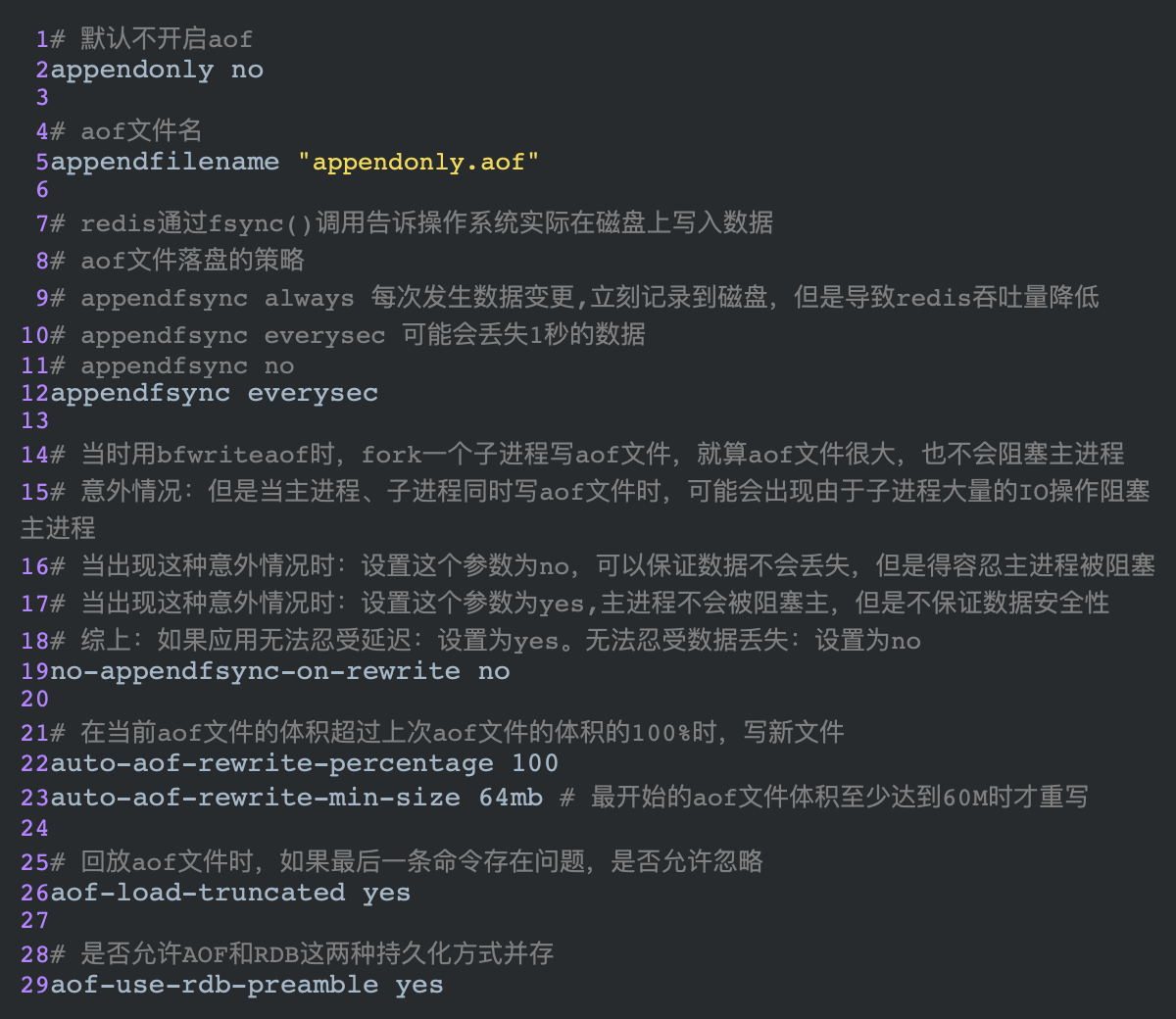
总结: AOF 记录的是对Redis数据库做更改的命令列表, 类似 MySQL 的 binlog.
一致性 Hash 算法
copy from https://juejin.cn/post/6844903670430040078#heading-1
总计: 一个选取集群内服务器的算法, 使其在大量的请求下可做到流量均匀的落到每台服务器上.
首先引入一个概念, 就是 hash 环, 其是 hash 的取值范围大小, 展开就是 范围下限-范围上限, 围起来则是一个环.
实现原理是, 对每个服务器取 hash, 记录下 hash 位置, 再对每个请求的特定信息(如ip, Redis Key)也取 hash, 在根据这两个 hash 大小关系, 顺时针(找比其更大的)寻找离得最近的服务器;
因为大量的请求会均匀的散落在 hash 环上, 这个是 hash 算法决定的性质, 同理大量的服务器节点也会均衡的散落在 hash 值范围内, 因此总体来看, 请求总是均匀的打落到每台服务器.
但这也引出一个问题, 就是 hash 值范围过大, 而服务器数量过少, 无法保证服务器均衡的散落在整个 hash 上, 因此引入虚拟节点, 使得每个虚拟节点的 hash 与原节点不一致, 然后每个节点创建大量的(比如1000)虚拟节点, 计算的 hash 则会均匀的散落在 hash 环上了.
再总结: 充分利用 hash 算法的特性, 以及加入取 hash 找距离近的服务器这个理念, 使得即使对服务器进行伸缩, 也可以降低被影响的key.
对比 HashSlot
了解了一致性Hash算法的特点后,我们也不难发现一些不尽人意的地方:
- 整个分布式缓存需要一个路由服务来做负载均衡,存在单点问题(如果路由服务挂了,整个缓存也就凉了)
- Hash环上的节点非常多或者更新频繁时,查找性能会比较低下
针对这些问题,Redis在实现自己的分布式集群方案时,设计了全新的思路:基于P2P结构的HashSlot算法,下面简单介绍一下:
使用HashSlot
类似于Hash环,Redis Cluster采用HashSlot来实现Key值的均匀分布和实例的增删管理。
首先默认分配了16384个Slot(这个大小正好可以使用2kb的空间保存),每个Slot相当于一致性Hash环上的一个节点。接入集群的所有实例将均匀地占有这些Slot,而最终当我们Set一个Key时,使用
CRC16(Key) % 16384来计算出这个Key属于哪个Slot,并最终映射到对应的实例上去。那么当增删实例时,Slot和实例间的对应要如何进行对应的改动呢?
举个例子,原本有3个节点A,B,C,那么一开始创建集群时Slot的覆盖情况是:
1
2
3
4节点A 0-5460
节点B 5461-10922
节点C 10923-16383
复制代码现在假设要增加一个节点D,RedisCluster的做法是将之前每台机器上的一部分Slot移动到D上(注意这个过程也意味着要对节点D写入的KV储存),成功接入后Slot的覆盖情况将变为如下情况:
1
2
3
4
5节点A 1365-5460
节点B 6827-10922
节点C 12288-16383
节点D 0-1364,5461-6826,10923-12287
复制代码同理删除一个节点,就是将其原来占有的Slot以及对应的KV储存均匀地归还给其他节点。
P2P节点寻找
现在我们考虑如何实现去中心化的访问,也就是说无论访问集群中的哪个节点,你都能够拿到想要的数据。其实这有点类似于路由器的路由表,具体说来就是:
- 每个节点都保存有完整的
HashSlot - 节点映射表,也就是说,每个节点都知道自己拥有哪些Slot,以及某个确定的Slot究竟对应着哪个节点。 - 无论向哪个节点发出寻找Key的请求,该节点都会通过
CRC(Key) % 16384计算该Key究竟存在于哪个Slot,并将请求转发至该Slot所在的节点。
总结一下就是两个要点:映射表和内部转发,这是通过著名的Gossip协议来实现的。
- 每个节点都保存有完整的
总结: 映射表记录了我这个 key 计算 hash 位于的槽属于哪个节点, 若是节点自身, 则处理请求, 若不是则转发到那个节点.
CAP理论
摘记一下: copy from https://mp.weixin.qq.com/s/zfkhQFEBkKSRsfKF63R94A
- C(Consistency 强一致性)
- A(Availability可用性)
- P(Partition tolerance分区容错性)
CAP 的理论核心是: 一个分布式的系统,不可能很好的满足一致性,可用性,分区容错性这三个需求,最多同时只能满足两个.因此CAP原理将nosql分成了三大原则:
- CA- 单点集群,满足强一致性和可用性,比如说oracle,扩展性收到了限制。
- CP- 满足一致性,和分区容错性Redis和MongoDB都属于这种类型。
- AP- 选择了可用性和分区容错性,他也是大多数网站的选择,容忍数据可以暂时不一致,但是不容忍系统挂掉。
Redis 配置文件
1 | ## 启动redis的方式 |


